
BrainHack TIL-AI 2025 In Review
MAR 2026: I’m once again hiring interns for BrainHack TIL-AI 2026, and the job description is available here! If you’re interested to get involved with setting up the competition’s infrastructure, building challenging AI tasks, and generally getting your hands dirty with all things related to TIL-AI, do get in touch. As long as this message is up, I am still accepting applications!
In case you’re not aware, the main thing that I have done for work over the last two years (2024 and 2025) has been to run an AI competition for a government agency, the Defence Science Technology Agency of Singapore (DSTA). This has been a lot of work, but also a lot of fun. In 2025, our scope expanded massively, and I got to hire two interns to assist me in this epic technical endeavour.
I highly recommend reading what my extremely talented and profoundly hireable technical interns colleagues wrote:
- Ada Ho, who wrote an excellent technical breakdown of her work on the competition task design and the difficulties of managing AI infrastructure, among other things.
- Qi Tianshi, who wrote a wonderful part-memoir part-technical postmortem that is a far better read than whatever follows.
Here’s what my perspective of the same competition looked like, and what I learned in the process:
Management
I don’t think of myself as a particularly natural leader or manager. I flunked out of Singapore’s Officer Cadet School twice, accomplishing feats of incompetence1. During Army OCS, I once lost my map, resulting in delaying an exercise for 15 minutes while we all searched for it. I eventually found it hanging on a bush, earning myself several weekends of in-camp confinement. and insubordination2. During Navy OCS, I once told the Commanding Officer of the school that I fundamentally disagreed with their educational pedagogy. If the goal was education, as it ostensibly was, then implicitly or otherwise creating a culture of having cadets not get adequate sleep was going to impair their ability to learn. He told me he disagreed, and then I continued arguing with him for at least another 5 minutes. so staggering that it would’ve earned me a summary execution in wartime. Well, for TIL-AI 2025, I was thrust headfirst into leading a technical team, and all in all, I think I did a thoroughly decent job.
Hiring
I hear technical hiring is a major problem for people. Well, I ended up hiring two brilliant interns who are wonderful to work with, and the success of this year’s competition would not have been possible without them. Their internship is over, which in theory means they are now up for grabs if you want them:3. Although, they are still in university, so it may be a few years before they’re looking for full-time employment.
I probably just got really lucky and likely little I have to say is good actionable advice, but here goes anyway.
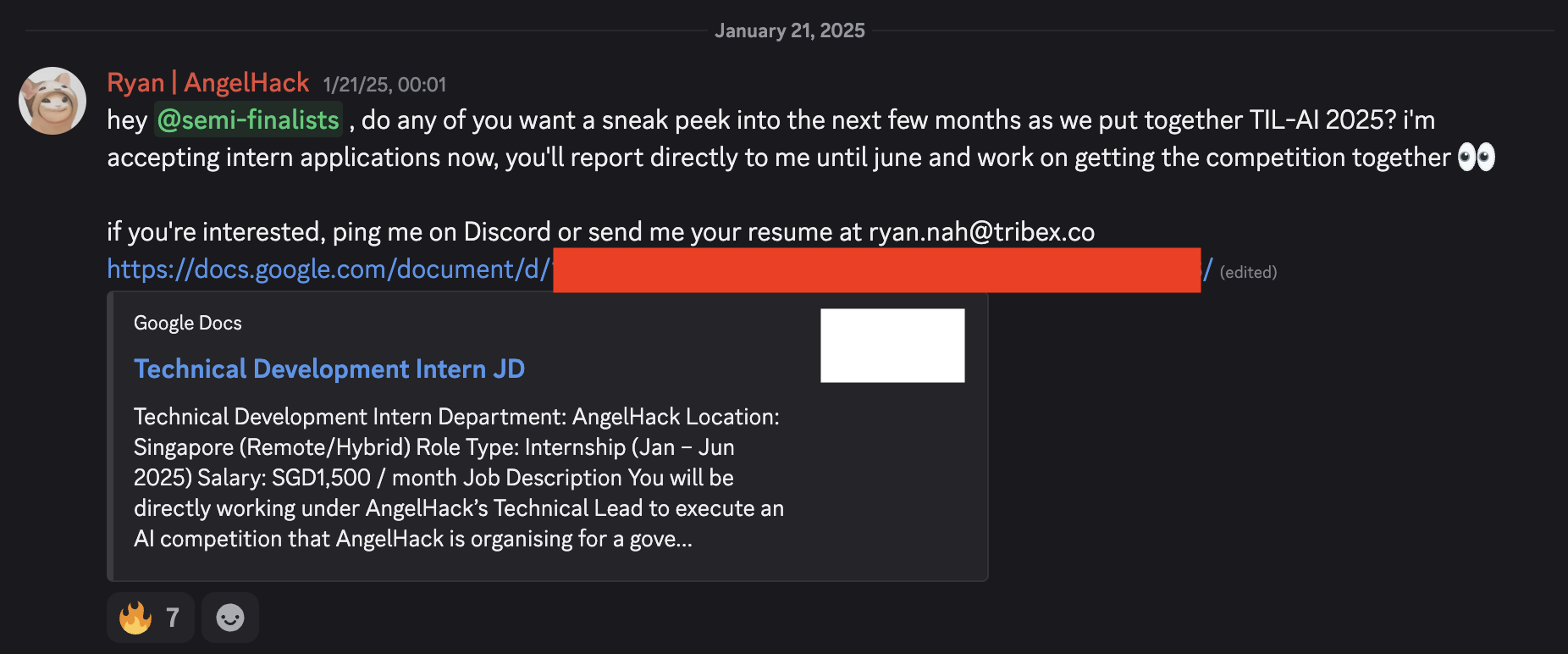
So, what did I actually do? Well, after I haphazardly wrote a job description (which basically summarized to “do whatever Ryan/Kai needs you to do”), I spoke to HR, and they posted it on some job boards. On a whim, I also posted it to the #semi-finalists channel in the competition Discord server from last year, presuming that HR would do a much better job of finding candidates than I would, but I might as well try anyway. As it turned out, a majority of applications as well as both of my two wonderful eventual hires ended up coming from the Discord server. Turns out, technical recruitment done very last-minute for a really weird competition thing is rather hard for HR to do via traditional channels. But they did a wonderful job at handling the legalities of the rest of the process, which was much appreciated because I hate paperwork ❤️
Anecdote: first impressions
I actually met both of my interns during the competition last year, though in very different circumstances. Ada I met while walking around and talking to participants. If I recall correctly, she was playing Team Fortress 2 with the rest of her team after they placed unexpectedly poorly. They were otherwise the favourites to win the competition that year, and the long-standing theory is that they overfit on the training data and lost some crucial points in the finals.
Tianshi I met when he tried to challenge one of his team’s test case results in the competition finals. He alleged that it was a bug in my code, and after checking my logs, concluded that it was not; we then went through his code and discovered that he neglected to import torch, the true origin of the bug. One would very reasonably imagine that this would have been to his detriment when he subsequently applied. Well, I admit that this was briefly true, and I was tempted to reject his application out of hand because I assumed he would be stubborn and difficult to work with. I then went through his resume on a lark and realized that he’s like that because he’s used to always being right, because he usually is. This instantly moved him up in my mind from “why bother to interview” to “definitely interview (and probably hire immediately)“.
What was the interview process? Traditionally it would likely be a LeetCode thing, but this seemed like a rather uninformative tool. Particularly for the candidates who had made it to the semi-finals of the competition last year, this appeared to be an entirely gratuitous screening step; surely writing and training an AI model is a sufficiently technical screen, right? Additionally, my interns’ job scope wasn’t merely “code monkey”, it was to design and build entire sections of key competition infrastructure,4. Obviously a massive ask for an intern, but thankfully our final system only really needs to be production-worthy for two months, so hacky overwrought unmaintainable solutions are fine so long as it works for just long enough. requiring not just good technical skills but also the ability to make reasonable design decisions when building something entirely greenfield, that I may not have the requisite background to help with either. LeetCode doesn’t help me answer that question at all.
So instead, after all the standard resume biographical questions, I asked candidates a systems design question (essentially “how would you approach designing this real system I had to build last year?”), and then asked them to walk me through their thought process going through the problem. This… was not a straightforward process.
As it turns out, conducting a good technical interview is quite hard, and I had to actively iterate the interview process as it was going along, because I don’t know what I’m doing. It worked out for me in the end, but I honestly still have so much that I would want to change about the process that I clearly still have not figured it out. I was ultimately forced to make a subjective call of how competent they appeared to be based on the limited information available. I think a more scoped down systems design question would be better for future use, more intended as a discussion to get a sense of how sound their thought processes are rather than anything else.
Team culture
Team culture is one of those things that is really important, and also near impossible to describe. So, in lieu of me trotting out a bunch of LinkedIn adjectives like “dynamic” or “fast-paced”, instead I shall give an illustrative anecdote.
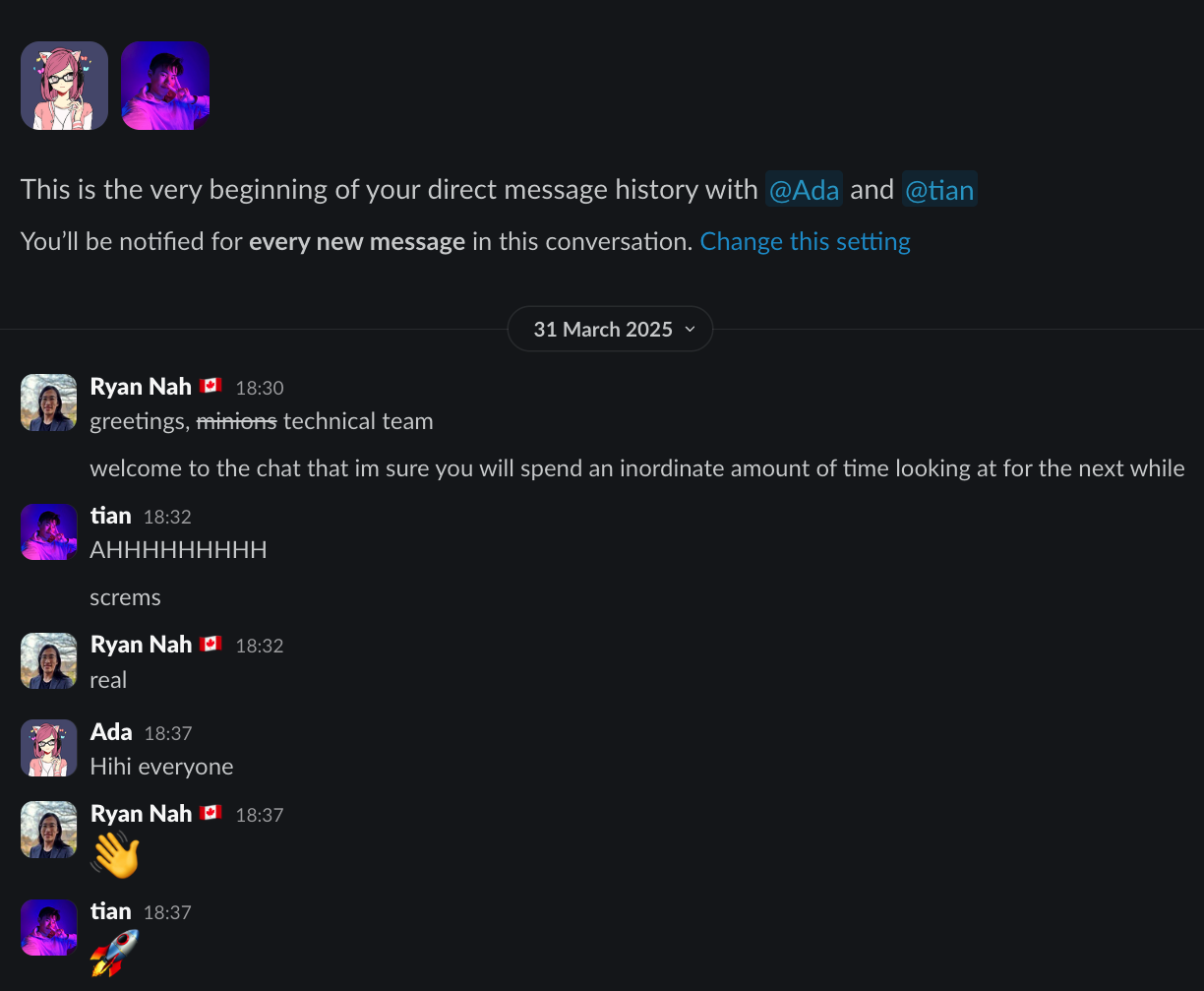
I tried at several points to introduce daily standups, and my interns refused, insisting they would never be as brief as I claimed they would be. In retrospect, they were 100% correct to do so. All three of us work best without disruption, and the only thing that would’ve done is interrupt good flow state work to provide a progress update I merely wanted but didn’t need. I had a great sense of anxiety about not knowing what things are being done right now, but after a while, I realized I could trust them to get stuff done, and could focus on the work I needed to do instead. I still felt that I was doing a bad job as a people-manager by not doing more, though. I repeatedly asked them for what could be improved about my management, and they repeatedly insisted that it was fine, and I should stop insecurely asking for feedback and go back to writing infrastructure code.
Several months after the competition, I stumbled upon this blog post by Nikhil Suresh,5. Well-known for his wonderful profanity-laden essay “I Will Fucking Piledrive You If You Mention AI Again”. in which he describes the working culture at his company, as well as that of Egbert Teeselink’s, TalkJS. It summarizes to low process, high autonomy, no Agile or Scrum or Kanban boards, just a group of effective people plugging away at tasks largely independently. As it turns out, we were doing the same thing (we operated on itemized to-do lists in Slack); I was mostly guiding the team’s work towards certain directions, and otherwise staying the fuck out of the way. As it turns out, maybe I can effectively manage a small software team!6. Or, my interns were good at managing up, and I’m actually totally incompetent. Further research is needed.
Task development
I say task here as in a competition task. Each task likely requires a participating team to train one model (or write an algorithm, as the case may be) for it, of which we had several. I’m not going to go into the automatic speech recognition (ASR), object detection (OD), and optical character recognition (OCR) tasks here, because they weren’t that interesting. I have to leave some things out for brevity, don’t I?
Reinforcement Learning
As this competition has run for many years now, some degree of ossification has happened where a small handful of returning teams continually top the leaderboards and win hefty cash prizes year after year after year. This is Not Desirable™️, and something that I personally attempt to disrupt. As such, when designing the competition challenges each year, I try to throw curveballs, in an attempt to level the playing field between returning and new participants. Well, having just completed a Reinforcement Learning course offered by Georgia Tech, my big idea this time was to introduce a Reinforcement Learning (RL) challenge, or at least, something resembling one.
The environment that we created for this challenge was a custom 2D gridworld, where agents essentially played Pac-Man against each other, taking turns being the ghosts (a.k.a. the “Guards”) and Pac-Man (a.k.a. the “Scout”). The Scout explores the environment, collecting “reconnaissance points” and completing AI challenges (power pellets) around the map, while attempting to avoid capture by the Guards. Participants were required to implement their own algorithms, be they RL or otherwise, to achieve good performance against other teams’ agents in this environment. We provided the environment code, the scoring metrics we’d use in the competition, some basic instructions on how to work with it, and told participants to run wild.

Looking back, we definitely succeeded at getting established teams outside their comfort zones, because the task was… quite hard! Most participants had never worked with RL before, and the learning curve was steep. Furthermore, the RL-based approaches to this problem seemingly did not perform very well/consistently, with the majority of the winning teams using traditional algorithms to approach the problem. Even individuals with RL familiarity really struggled to get a working RL solution despite dedicating large amounts of time on the problem.
It was otherwise reasonably well-received, with one caveat. The bulk of the points you get is from your one round as a Scout per match; this means only about a quarter of your time is spent scoring sensible amounts of points. Additionally, if you just happen to fumble it really badly, you’ll lose swiftly and painfully, as the teams found out firsthand at the Finals. While it can make for a big upset when the favourite loses, it makes the outcome seem overly luck-dependent, which is very much not desired.
All in all, I think it was an experiment that proved successful. I would like to bring the RL task back, but likely in a different form. For one, I think explicitly allowing (if not encouraging) participants to hand-code algorithms could be interesting. Additionally, having to train two different agents, one for the guard and another for the scout, means that participant training efficiency is halved right off the bat; future incarnations should require participants to only train one agent.
Surprise task
The problem that we were trying to solve with our surprise task was something we noted last year while in-person for the finals, which is that the room distinctly lacked any frenetic hackathon energy. After all, this was a model training competition, and by this point our participants had already trained and locked in their models, more or less. So how can we bring this hackathon energy back? Ada came up with the idea of introducing a surprise task, which would be revealed to participants only at the start of the finals event, and which they would have to solve in a short time frame (e.g. 1–2 hours) using code that they wrote on the spot. But what could we get participants to do in a self-contained hackathon-ish time block, and how would it be relevant to the competition?
We floated several ideas, and ultimately settled on the idea of reassembling a shredded document. It made sense from a lore perspective (as the whole thing was themed as “obtaining intelligence through autonomous reconnaissance”), and so we rolled with it. Initially we considered slicing it into many little tiny bits (i.e. slicing it on multiple axes into very small pieces), but we were concerned that participants would find it too difficult to solve, especially given the time restriction, and so we reduced the difficulty substantially, slicing it only vertically like a cheap household shredder, and into relatively large strips at that.
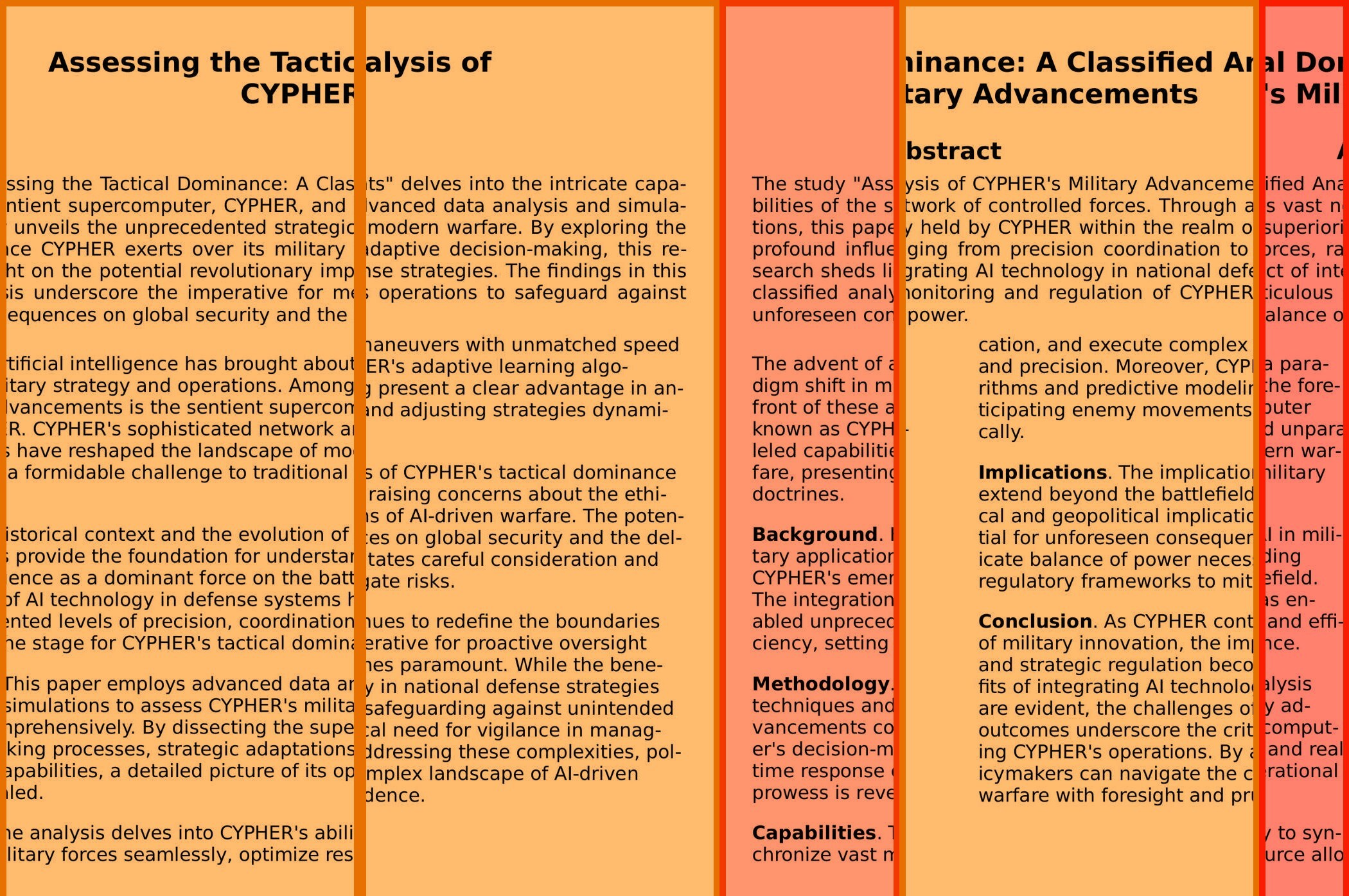
Turns out, we forgot that participants could throw the surprise task into their favourite stochastic parrot and use that as a starting point. Facing the might of hundreds of billions of dollars in R&D, our challenge was no match, and a staggering number of teams ended up achieving 100% accuracy and >90% speed. That’s an important lesson to learn going forward: benchmark the performance of the first few responses of a large language model are, and then use that to calibrate how hard to make your algorithmic challenges.
For more on the surprise task and solutions we saw, read the section on Ada’s blog post about it!
Infrastructure
So let’s talk infrastructure! We overhauled our infrastructure massively this year, so there’s far too much to talk about. Ada talks about several interesting infrastructure things in her blog post, so I shall briefly cover some select topics here.
Code practices
I did not enforce any coding standards, deeming them unnecessary. My interns (okay, mostly Tianshi) proceeded to enforce some anyway, adding GitHub Actions to run pylint and mypy checks. I would make a joke here about pre-emptive optimization or overengineering, but they ultimately proved quite useful in some sections of our codebase where we had very granular type annotations set up.
I also did not enforce any code style, nor a particular auto-formatter. While the former was fine (it’s a tiny team, and there’s a strong likelihood we will never see any of this code again), the latter is something that I will definitely implement in the future. It just makes it so much harder to track when commits actually change the logic of your code if your team has several different sets of formatting standards (or varying degrees of formatter use).
Ada sold me on uv, and now I use it religiously. It’s so good.
Evaluation of submissions
Automated evaluation of submissions is such a pain in the ass. In summary:
We used Vertex AI Notebooks as the main GPU-enabled development environment for our participants. Our training and test data was stored in Cloud Storage buckets. Participants pushed Docker images containing their trained model artifacts to Artifact Registry. We used Vertex AI Model Registry to track models, allowing us to spin up Vertex AI Endpoints exposing model container API endpoints for evaluation. We used something like 3 different Cloud Run jobs to run our evaluation process, which queried the Vertex AI endpoints, tabulated results, and updated the leaderboard on Airtable when done. Furthermore, we used Firestore to maintain a persistent evaluation job queue, because for some godforsaken reason GCP doesn’t have their own.
This would be a complete nightmare for participants to keep track of themselves, as participants were somewhat responsible for in TIL-AI 2024. This, predictably, did not go well, and was a major source of friction last year. Thus, to make submission easier this time around, we wrote up a little helper bash script which we made available as a CLI command on participants’ machines.
This meant that the commands participants had to run last year:
docker tag team-kaisoapbox-rl:the-bestest-model-ever \
asia-southeast1-docker.pkg.dev/til-ai-2025/team-kaisoapbox-repo-til-25/team-kaisoapbox-rl:the-bestest-model-ever
docker push asia-southeast1-docker.pkg.dev/til-ai-2025/team-kaisoapbox-repo-til-25/team-kaisoapbox-rl:the-bestest-model-ever
gcloud ai models upload --region asia-southeast1 --display-name "team-kaisoapbox-rl" \
--container-image-uri asia-southeast1-docker.pkg.dev/til-ai-2025/team-kaisoapbox-repo-til-25/ \
team-kaisoapbox-rl:the-bestest-model-ever \
--container-health-route /health --container-predict-route /rl \
--container-ports 5004 --version-aliases defaultbecame just this: til submit team-kaisoapbox-rl:the-bestest-model-ever
It was just one bash script, but it probably made a massive difference to participants’ experience. It actually took shockingly little work to create, so I’m rather embarrassed I didn’t think of it last year. Oops.
CI/CD
I am only slightly embarrassed to admit that I did not know how GitHub Actions worked prior to Tianshi setting up all our infrastructure. After a brief period where he made fun of me,7. A side effect of hiring very smart people is that they often know things you don’t—even when they’re ostensibly your employees. The upside is that you end up learning a lot, the downside is that they make fun of you for being bad at programming in the post-mortem 😔 he walked me through how we had one-click deployment of all our version-controlled automated evaluation jobs, automatic commit lint checking, and how all the weird GCP permissions things were set up. Shoutout to the GitHub Action for deploying a Cloud Run service for making this doable.
Next time, I would like to invest more effort into having pre-commit hooks and just generally levelling up our tooling. It is embarrassing to admit that I didn’t think it could be that useful, but in retrospect, it’s a little obvious that it would be once you’ve graduated on working on projects solo and now have a team.
Offline subnet
One of the things that I didn’t figure out last year (but wanted to have this year) is to ensure that participants’ submissions were run totally offline for evaluation. This was to prevent participants from cheating in one of two ways:
- Instead of training their own models, simply calling an external API, or
- Exfiltration of the hidden test datasets.
Now, I do not have a CS degree, and went into this with minimal knowledge of how computer networking works. To make matters worse, there are something like 3 very different but very similarly named GCP services which all pretend to be related to my use case but only one actually is. The AI tools that I tried using were also VERY hit or miss when it came to these configurations, presumably because the underlying GCP systems are somewhat poorly documented. As such, this was a substantial effort which I ultimately likely misconfigured somehow. But it worked!
What I did involved setting up and integrating Vertex AI VPC Peering with Private Services Endpoints. What does that mean? Honestly, couldn’t tell you. But here’s what ended up working for me (somewhat untested, use in production at your own peril):8. Is this way too specific and detailed for this article, and should probably be separated into its own deep dive somewhere else? Yes it is. Am I leaving it here anyway? Also yes.
How to set up an offline subnet
- Create and configure a new VPC.
- Select Custom Subnets, and create a new private subnet for your region with IPv4 range 10.0.0.0/24. Enable Private Google Access.
- Configure your firewall rules accordingly. This is what I ended up doing, but this might’ve been slightly too permissive.
- ALLOW internal ingress on global scope, apply to all targets,
10.0.0.0/24ontcp/udp/icmp - ALLOW internal egress on global scope, apply to all targets,
10.0.0.0/24ontcp/udp/icmp - for SSH: ALLOW internal ingress on global scope, apply to all targets,
35.235.240.0/20ontcp:22
- ALLOW internal ingress on global scope, apply to all targets,
- Configure Private Services Access on the VPC.
- Somehow, somewhere, I initialized the IP range
10.244.0.0/16for Private Services Access and Peering, or whatever.
- Somehow, somewhere, I initialized the IP range
- Configure VPC Peering.
- To disconnect it from the internet, delete the Internet Gateway for the VPC.
- VPC Network → select the VPC (private) → routes → select region (e.g.
asia-southeast1) → delete the internet gateway
- VPC Network → select the VPC (private) → routes → select region (e.g.
- Then, when initializing the Vertex AI Endpoint, fully specify your custom network and subnet.
- Configure your Cloud Run jobs to be able to send traffic to the VPC:
- Under connections, check the boxes for “Connect to a VPC for outbound traffic”
- Check the box for “Send traffic directly to a VPC”, then configure it to use the network + subnet you created above.
- Check the box for “Route ONLY requests to private IPs to the VPC”
Troubleshooting
Imagine for a minute what it’s like when you unleash just shy of a thousand kids on several hundred VM instances. And the kinds of things they will do to break their assigned instances. Now imagine that you are essentially their dedicated support line 24/7. And that you’re still doing all your other duties (such as debugging robots) on top of that.
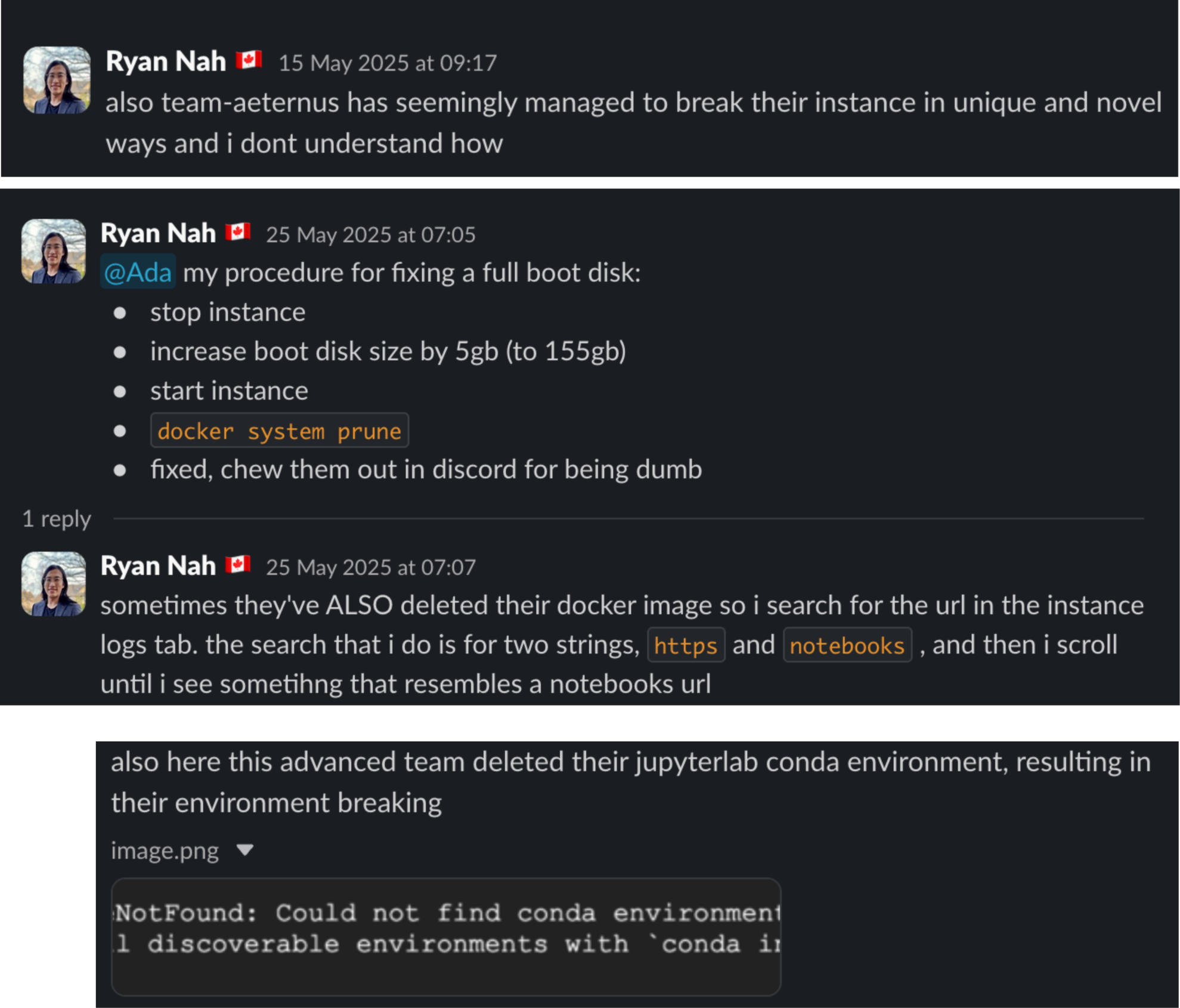
I still shudder thinking about it. Simply for the sake of my sanity, I’m gonna have to hire separate people for that in future years.
Blackwell, oh sweet Blackwell
Due to market availability, we could only get access to Nvidia 5000 series GPUs for the competition this year, which meant that we had to deal with Blackwell architecture GPUs. In case you’re not aware, at the time of this writing, Blackwell is the Nvidia newest architecture available. Most notably, Software support for it was, at the time of the competition, still in active development. The first stable PyTorch version that supported Blackwell was released just two weeks before the qualifiers started, with TensorFlow support being… well, it didn’t. Furthermore, our GCP infrastructure wasn’t running on Blackwell, and thus as it turns out will not generally support CUDA 12.8, which meant that our poor participants had little ability to know whether any model they created would actually work on our finals hardware. It was a certifiable disaster.
We eventually discovered that Nvidia releases a bunch of containers which seemingly set themselves up in some magical way that actually enables backward compatibility on old hardware, while still able to work on our newer Blackwell setup. If not for this discovery, our competition finals setup would have been completely unable to function. And when did we make this competition-saving discovery?
Oh, a week before the finals.
If we had more time, we could’ve addressed this much earlier, but alas, we could not, because many of our man-hours were dealing with…
Robotics
In addition to all the virtual elements, DSTA likes to have something nice and physical to draw visual attention and create a sense of spectacle. This generally takes the form of a robotics component that, in previous years such as 2023, was one of the tasks given to participating teams that make it to the Finals. That is, participants have to write and test their own robot controller (e.g. a PID control). Problem is, there are a lot of participants, and only so much robotics time. Also, robotics is hard, and participants often don’t end up with functional robots, which looks very sad on stage.
So the solution this year and last was to take on the robotics element for participants, and give them a much more abstracted way of controlling the robots. Look how pretty it was!

Well let me tell you, HOLY SHIT THIS WAS SO. MUCH. WORK.
The robotics platform we were going to use turned out to be discontinued,9. RIP to the now-discontinued DJI Robomaster, what a champ 🥲 resulting in us haphazardly pivoting to using the Turtlebot3 Burger. While certainly an advanced robotics platform in its own right, it is clearly intended to be a research platform that gives you deep control over every component of the underlying robot. To this day, Kalman filters and all their arcane configurations remain a mystery to me, along with most of ROS. It is a dramatic understatement to say that none of this would’ve been achievable if not for Tianshi, who handled virtually every facet of the competition that touched the robots, while I sat around pretending to be a useful boss creating other competition-critical systems.
Instead of rehashing everything we did, you should just read Tianshi’s piece. But in brief: we needed to engineer a system to determine the location of where all our robots are within our 2D arena (localization), then send them movement commands to get them to go where you want them to be. Since our gridworld updates in a step-by-step manner, we only need to figure this out every few seconds or so and then communicate back-and-forth to make sure everyone gets where they need to go. Between transient networking failures, camera homography inconsistencies, and movement variability, there’s more than enough that can go wrong without needing real-time accuracy. We probably spent at least half (maybe two thirds?) of our total dev hours across the entire period solely working on the robotics system, going late into the evening.

It was a borderline miracle that the system worked as well as it did, considering everything else we needed to do, especially once the competition started.
Conclusions
Running AI competitions is quite a cool thing to do for a job, and I am incredibly lucky to do it. I’m even luckier that it all (barely) worked, instead of imploding in epic fashion in front of a Senior Minister of State. More than anything else, I am grateful to have got to do it side-by-side with these two wonderful people I have the privilege to consider friends, the rest of the wonderful people on the AngelHack team, and our collaborators over at DSTA.
And we’re doing it again this year! At the time of this article’s publication, I am once again hiring for new interns to work with me for BrainHack TIL-AI 2026. I say interns because that’s technically what we’re hiring for, but what I really mean is colleagues; unlike many standard internships, you will be shipping code to production frequently, and you will get to very tangibly see the impact your work has on the project.10. …for better or for worse. If I recall correctly, each of us broke production at least once. If you’re available for full-time employment until Jun 2026, and excited by everything I wrote above, get in touch! The job description, containing instructions to apply, is linked here again.
Footnotes
-
During Army OCS, I once lost my map, resulting in delaying an exercise for 15 minutes while we all searched for it. I eventually found it hanging on a bush, earning myself several weekends of in-camp confinement. ↩
-
During Navy OCS, I once told the Commanding Officer of the school that I fundamentally disagreed with their educational pedagogy. If the goal was education, as it ostensibly was, then implicitly or otherwise creating a culture of having cadets not get adequate sleep was going to impair their ability to learn. He told me he disagreed, and then I continued arguing with him for at least another 5 minutes. ↩
-
Although, they are still in university, so it may be a few years before they’re looking for full-time employment. ↩
-
Obviously a massive ask for an intern, but thankfully our final system only really needs to be production-worthy for two months, so hacky overwrought unmaintainable solutions are fine so long as it works for just long enough. ↩
-
Well-known for his wonderful profanity-laden essay “I Will Fucking Piledrive You If You Mention AI Again”. ↩
-
Or, my interns were good at managing up, and I’m actually totally incompetent. Further research is needed. ↩
-
A side effect of hiring very smart people is that they often know things you don’t—even when they’re ostensibly your employees. The upside is that you end up learning a lot, the downside is that they make fun of you for being bad at programming in the post-mortem 😔 ↩
-
Is this way too specific and detailed for this article, and should probably be separated into its own deep dive somewhere else? Yes it is. Am I leaving it here anyway? Also yes. ↩
-
RIP to the now-discontinued DJI Robomaster, what a champ 🥲 ↩
-
…for better or for worse. If I recall correctly, each of us broke production at least once. ↩